

✔️ 들어가며
이번 주는 심화 자료구조 학습 주차였다. 그래프, DFS, BFS, 트리, 이진 트리에 대한 개념 공부와 알고리즘 공부를 진행하게 되었다. 기본 자료구조 주차에 비해서 난이도가 많이 올라갔다고 느꼈던 한 주였다. 문제를 해결한 방법과, 배운 점 및 알아야 할 점에 관련하여 글을 작성해보려고 한다.
✔️ 그래프 & DFS 활용
[Baekjoon] 2667. 단지 번호 붙이기 - https://www.acmicpc.net/problem/2667
2667번: 단지번호붙이기
<그림 1>과 같이 정사각형 모양의 지도가 있다. 1은 집이 있는 곳을, 0은 집이 없는 곳을 나타낸다. 철수는 이 지도를 가지고 연결된 집의 모임인 단지를 정의하고, 단지에 번호를 붙이려 한다. 여
www.acmicpc.net

from sys import stdin
N = int(input())
dx = [0, 0, 1, -1]
dy = [1, -1, 0, 0]
total = 0 # 총 집 구역의 개수
DFS_count = 0 # DFS의 깊이 개수 - 몇번 recursive 했는지
DFS_count_lst = [] # DFS의 깊이 개수 출력을 위해서 담아 둘 곳
# 2차원 리스트(행렬) 생성
board = []
for i in range(N):
readline = stdin.readline().strip()
board.append(list(readline))
print(board)
len = len(board)
def DFS(row, col):
if row < 0 or row >= len or col < 0 or col >= len or board[row][col] == '0':
return
# 상하좌우 방문처리
board[row][col] = '0'
global DFS_count
DFS_count += 1
for i in range(4):
nx = row + dx[i]
ny = col + dy[i]
DFS(nx, ny)
# 탐색 시작
for row in range(len):
for col in range(len):
if board[row][col] == '1':
DFS(row, col)
DFS_count_lst.append(DFS_count)
DFS_count = 0
total += 1
print(total)
for count in sorted(DFS_count_lst):
print(count)문제 설명
이 문제는 다른 문제로 비교하면 '섬의 개수 구하기' 문제랑 같다. 인접행렬에서 0으로 둘러싸여 있는 집의 개수를 구하고, 그 집의 size까지 구하는 문제이다.
해결 방법
해결했던 방법은, 인접행렬을 하나하나 순회하면서 '0' 이면 지나가고, '1' 을 만나게 되면 DFS(깊이 우선 탐색)로 해당 부분의 상, 하, 좌, 우를 탐색했다. '1'이 존재하면 '0'으로 바꿔주며 탐색을 진행했고, 탐색 범위가 행렬의 크기를 벗어나거나 '1'이 아니면 DFS 함수가 return 되도록 설정했다.
💡 DFS의 장점과 단점
- 장점
- 현 경로상의 노드들만 기억하면 되므로 저장공간 수요가 비교적 적다.
- 목표 노드가 깊은 단계에 있을 경우 BFS보다 해를 빨리 구할 수 있다.
- 단점
- 해가 없는 경로가 깊을 경우 탐색시간이 오래 걸릴 수 있다.
- 얻어진 해가 최단 경로가 된다는 보장이 없다.
- 깊이가 무한히 깊어지면 스택오버플로우가 날 수 있게 된다.
✔️ 그래프 & BFS 활용
[Leetcode] 207. Course Schedule - https://leetcode.com/problems/course-schedule
LeetCode - The World's Leading Online Programming Learning Platform
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
# 수업 prerequisites = [[a,b]] 이 주어지면, a를 수강하기 위해서는 b를 먼저 수강해야한다.
# 선행 수업을 마치며 다음 수업을 모두 진행할 수 있는지, 못 하는지 구하는 문제.
# 그래프가 cycle이 생기면 안된다. -> 서로가 서로를 선행해야하는 수업이면 안된다.
# 수업 '0'을 선행하고 '1'을 진행할 수 있다. True
Example 1:
Input: numCourses = 2, prerequisites = [[1,0]]
Output: true
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0. So it is possible.
# 서로가 서로를 선행해야하는 상황. False
Example 2:
Input: numCourses = 2, prerequisites = [[1,0],[0,1]]
Output: false
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0,
and to take course 0 you should also have finished course 1. So it is impossible.class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
# 그래프 초기화
graph = defaultdict(list)
indegree = [0] * numCourses # 강의의 선행 강의의 수를 담기 위한 리스트
for next, pre in prerequisites:
graph[pre].append(next)
indegree[next] += 1
# 선행 강의 수(indegree)가 0 인것부터 그래프를 탐색한다
start = [i for i in range(numCourses) if indegree[i] == 0]
q = deque(start)
while q:
pre = q.popleft()
for next in graph[pre]:
indegree[next] -= 1
# 선수 강의가 0개이면 다시 큐에 넣는다. 다음 노드를 탐색하기 위함.
if indegree[next] == 0:
q.append(next)
# [0, 0, 0]
# 위의 과정을 마쳤을 때 아직 선수 강의가 남아있는 강의가 있을 경우에는 False를 리턴
for course in indegree:
if course != 0:
return False
return True문제 설명
어떤 수업을 듣기 위해서는 '선행'되어야 하는 수업이 존재한다. 선행 수업을 들으며 수업을 끝까지 진행했을 때 모든 수업을 들을 수 있으면 True를 반환, 들을 수 없다면 False를 반환하는 문제이다.
해결 방법
처음에 문제를 어떻게 풀어야 할지 감을 못 잡았다. 뭔가 수업에 대한 그래프를 그려서 해결해야 할 것 같은데.. 아이디어가 떠오르지 않았다. 그래서 찾아보던 도중, '위상 정렬' 이라는 키워드를 찾을 수 있게 되었다. 출처는 아래 블로그이다.
[Algorithms] 위상 정렬
정렬을 떠올릴 때 보통 배열과 같이 일련의 원소에 대한 정렬을 생각하곤 한다. 그러나 특정한 그래프에서는 순차적인 처리가 요구되는 경우가 있다. 따라서 이번 포스팅에서는 그래프를 정렬
www.lifencoding.com
💡 위상 정렬
위상 정렬이란 '순서가 정해져 있는 작업'을 차례로 수행해야 할 때, 그 순서를 결정해 주기 위하여 사용하는 알고리즘이다.
각 노드들에 indegree를 이용한다. indegree란 특정 노드에 대해 다른 노드로부터 들어오는 간선의 개수를 뜻한다.
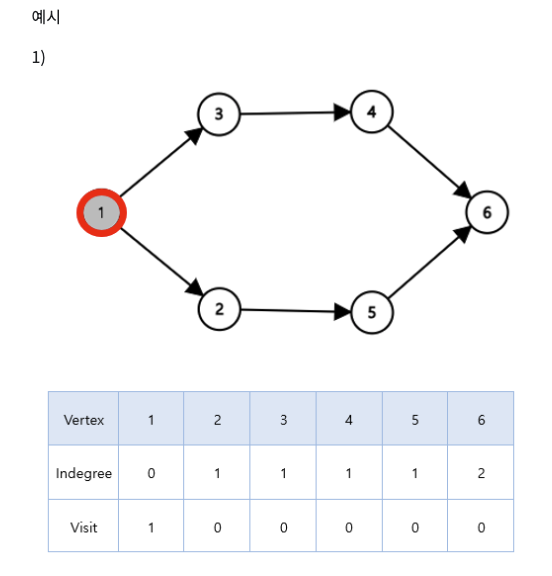



위 indegree에서 아이디어를 얻었다.
그래프를 구현하고, indegree에 선행해야 하는 수업의 개수를 저장했다. 선행 해야하는 수업이 '0' 개인 노드를 찾아서, BFS 탐색으로 모든 노드를 탐색하면서 해당 노드를 탐색할 때마다 수업의 개수를 '-1' 개 해주었다.
올바르게 수업이 진행된다면 모든 indegree는 개수가 '0'이 되어야 하는 것이다. 그래프가 싸이클이 있거나 선행 수업이 올바르게 진행되지 않았다면 indegree에 '0'이 아닌 수가 있을 것이다. 그럼 False를 return 하도록 하였다.
💡 BFS 장점과 단점
- 장점
- 모든 경로를 탐색하기에 여러 해가 있을 경우에도 최단 경로임을 보장한다.
- 노드의 수가 적고, 깊이가 얕은 해가 존재할 때 유리하다.
- 최단 경로가 존재하면 깊이가 무한정 깊어진다고 해도 답을 찾을 수 있다.
- 단점
- 노드의 수가 많을수록 탐색 가지가 급격히 증가함에 따라 보다 많은 메모리를 필요로 하게 된다.
✔️ 이진 트리(BST) & DFS 활용
[Leetcode] 700. Search in a Binary Search Tree - https://leetcode.com/problems/search-in-a-binary-search-tree/description/
LeetCode - The World's Leading Online Programming Learning Platform
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
def DFS(node):
if not node:
return None
# 값 일치하는 것 찾으면 node return
if node.val == val:
return node
# 현재 노드의 값이 타겟보다 크면 왼쪽 으로 탐색
if node.val > val:
return DFS(node.left)
# 현재 노드의 값이 타겟보다 작으면 오른쪽 으로 탐색
if node.val < val:
return DFS(node.right)
return DFS(root)문제 설명
BST(Bianry Search Tree)가 주어진다. 어떠한 수 val 이 주어지는데, val 값에 해당하는 노드를 반환하는 문제이다.
문제 해결
트리를 최상위 루트 노드부터 DFS로 탐색한다. BST(이진 탐색 트리)는 부모의 키 값이 왼쪽 자식 노드의 키 값보다 크며, 부모의 키 값이 오른쪽 자식 노드의 키 값보다 작다.
그래서 트리를 탐색할 때, 우리가 찾는 'val' 값이 본인 노드보다 크다면 오른쪽 으로 탐색, 작다면 왼쪽으로 탐색하면 된다.
이렇게 탐색하게 되면 전체 노드를 탐색하는 것보다 시간 복잡도가 O(N) -> O(log N)으로 줄어들게 된다.
💡 BST(Binary Search Tree)의 단점
여기서 알아 둬야 할 점은, BST의 시간복잡도가 무조건 O(log N)이 아니라는 점이다. 아래 그림을 보자.

이진 탐색트리에 새로운 노드가 삽입되면 부모 노드보다 작은 값은 왼쪽, 큰 값은 오른쪽으로 추가하게 된다.
위 그림처럼, 최악의 경우는 이진 탐색트리가 한쪽으로 치우치게 되는데, 이를 Skewed Binary Search Tree(편향 이진 탐색 트리)라고 한다. 이 경우는 특정 노드를 탐색하는 시간이 O(N)이 소요된다.
이를 개선하기 위해 나온 트리가 균형 이진 탐색 트리(Balanced Binary Search Tree)이다.
✔️ 글을 마치며
문제를 풀 때, DFS를 사용할지 BFS를 사용할지 구분을 지어야 할 것 같다. 최단 거리 문제 같은 경우는 BFS로 풀고, 이동과정에 가중치나 조건이 붙는다면 DFS로 푸는 게 좋을 것 같다. 미로 찾기로 예를 들면, 미로 찾기의 출구 최단 거리를 구하는 문제는 BFS로 풀고, 미로 찾기의 출구가 존재하는지 안 하는지의 여부는 DFS로 풀면 좋을 것 같다.
또한 알고리즘 문제를 풀 때, 문제를 해결하는 데에만 초점을 맞추지 말자. 그 문제 속에서 배울 수 있는 개념들이 많다. 자료구조의 장점과 단점을 확실하게 공부하고, 상황에 맞는 최적의 자료구조와 알고리즘을 찾는 연습이 더 필요할 것 같다.
✔️ 들어가며
이번 주는 심화 자료구조 학습 주차였다. 그래프, DFS, BFS, 트리, 이진 트리에 대한 개념 공부와 알고리즘 공부를 진행하게 되었다. 기본 자료구조 주차에 비해서 난이도가 많이 올라갔다고 느꼈던 한 주였다. 문제를 해결한 방법과, 배운 점 및 알아야 할 점에 관련하여 글을 작성해보려고 한다.
✔️ 그래프 & DFS 활용
[Baekjoon] 2667. 단지 번호 붙이기 - https://www.acmicpc.net/problem/2667
2667번: 단지번호붙이기
<그림 1>과 같이 정사각형 모양의 지도가 있다. 1은 집이 있는 곳을, 0은 집이 없는 곳을 나타낸다. 철수는 이 지도를 가지고 연결된 집의 모임인 단지를 정의하고, 단지에 번호를 붙이려 한다. 여
www.acmicpc.net
from sys import stdin
N = int(input())
dx = [0, 0, 1, -1]
dy = [1, -1, 0, 0]
total = 0 # 총 집 구역의 개수
DFS_count = 0 # DFS의 깊이 개수 - 몇번 recursive 했는지
DFS_count_lst = [] # DFS의 깊이 개수 출력을 위해서 담아 둘 곳
# 2차원 리스트(행렬) 생성
board = []
for i in range(N):
readline = stdin.readline().strip()
board.append(list(readline))
print(board)
len = len(board)
def DFS(row, col):
if row < 0 or row >= len or col < 0 or col >= len or board[row][col] == '0':
return
# 상하좌우 방문처리
board[row][col] = '0'
global DFS_count
DFS_count += 1
for i in range(4):
nx = row + dx[i]
ny = col + dy[i]
DFS(nx, ny)
# 탐색 시작
for row in range(len):
for col in range(len):
if board[row][col] == '1':
DFS(row, col)
DFS_count_lst.append(DFS_count)
DFS_count = 0
total += 1
print(total)
for count in sorted(DFS_count_lst):
print(count)문제 설명
이 문제는 다른 문제로 비교하면 '섬의 개수 구하기' 문제랑 같다. 인접행렬에서 0으로 둘러싸여 있는 집의 개수를 구하고, 그 집의 size까지 구하는 문제이다.
해결 방법
해결했던 방법은, 인접행렬을 하나하나 순회하면서 '0' 이면 지나가고, '1' 을 만나게 되면 DFS(깊이 우선 탐색)로 해당 부분의 상, 하, 좌, 우를 탐색했다. '1'이 존재하면 '0'으로 바꿔주며 탐색을 진행했고, 탐색 범위가 행렬의 크기를 벗어나거나 '1'이 아니면 DFS 함수가 return 되도록 설정했다.
💡 DFS의 장점과 단점
- 장점
- 현 경로상의 노드들만 기억하면 되므로 저장공간 수요가 비교적 적다.
- 목표 노드가 깊은 단계에 있을 경우 BFS보다 해를 빨리 구할 수 있다.
- 단점
- 해가 없는 경로가 깊을 경우 탐색시간이 오래 걸릴 수 있다.
- 얻어진 해가 최단 경로가 된다는 보장이 없다.
- 깊이가 무한히 깊어지면 스택오버플로우가 날 수 있게 된다.
✔️ 그래프 & BFS 활용
[Leetcode] 207. Course Schedule - https://leetcode.com/problems/course-schedule
LeetCode - The World's Leading Online Programming Learning Platform
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
# 수업 prerequisites = [[a,b]] 이 주어지면, a를 수강하기 위해서는 b를 먼저 수강해야한다.
# 선행 수업을 마치며 다음 수업을 모두 진행할 수 있는지, 못 하는지 구하는 문제.
# 그래프가 cycle이 생기면 안된다. -> 서로가 서로를 선행해야하는 수업이면 안된다.
# 수업 '0'을 선행하고 '1'을 진행할 수 있다. True
Example 1:
Input: numCourses = 2, prerequisites = [[1,0]]
Output: true
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0. So it is possible.
# 서로가 서로를 선행해야하는 상황. False
Example 2:
Input: numCourses = 2, prerequisites = [[1,0],[0,1]]
Output: false
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0,
and to take course 0 you should also have finished course 1. So it is impossible.
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
# 그래프 초기화
graph = defaultdict(list)
indegree = [0] * numCourses # 강의의 선행 강의의 수를 담기 위한 리스트
for next, pre in prerequisites:
graph[pre].append(next)
indegree[next] += 1
# 선행 강의 수(indegree)가 0 인것부터 그래프를 탐색한다
start = [i for i in range(numCourses) if indegree[i] == 0]
q = deque(start)
while q:
pre = q.popleft()
for next in graph[pre]:
indegree[next] -= 1
# 선수 강의가 0개이면 다시 큐에 넣는다. 다음 노드를 탐색하기 위함.
if indegree[next] == 0:
q.append(next)
# [0, 0, 0]
# 위의 과정을 마쳤을 때 아직 선수 강의가 남아있는 강의가 있을 경우에는 False를 리턴
for course in indegree:
if course != 0:
return False
return True문제 설명
어떤 수업을 듣기 위해서는 '선행'되어야 하는 수업이 존재한다. 선행 수업을 들으며 수업을 끝까지 진행했을 때 모든 수업을 들을 수 있으면 True를 반환, 들을 수 없다면 False를 반환하는 문제이다.
해결 방법
처음에 문제를 어떻게 풀어야 할지 감을 못 잡았다. 뭔가 수업에 대한 그래프를 그려서 해결해야 할 것 같은데.. 아이디어가 떠오르지 않았다. 그래서 찾아보던 도중, '위상 정렬' 이라는 키워드를 찾을 수 있게 되었다. 출처는 아래 블로그이다.
[Algorithms] 위상 정렬
정렬을 떠올릴 때 보통 배열과 같이 일련의 원소에 대한 정렬을 생각하곤 한다. 그러나 특정한 그래프에서는 순차적인 처리가 요구되는 경우가 있다. 따라서 이번 포스팅에서는 그래프를 정렬
www.lifencoding.com
💡 위상 정렬
위상 정렬이란 '순서가 정해져 있는 작업'을 차례로 수행해야 할 때, 그 순서를 결정해 주기 위하여 사용하는 알고리즘이다.
각 노드들에 indegree를 이용한다. indegree란 특정 노드에 대해 다른 노드로부터 들어오는 간선의 개수를 뜻한다.
위 indegree에서 아이디어를 얻었다.
그래프를 구현하고, indegree에 선행해야 하는 수업의 개수를 저장했다. 선행 해야하는 수업이 '0' 개인 노드를 찾아서, BFS 탐색으로 모든 노드를 탐색하면서 해당 노드를 탐색할 때마다 수업의 개수를 '-1' 개 해주었다.
올바르게 수업이 진행된다면 모든 indegree는 개수가 '0'이 되어야 하는 것이다. 그래프가 싸이클이 있거나 선행 수업이 올바르게 진행되지 않았다면 indegree에 '0'이 아닌 수가 있을 것이다. 그럼 False를 return 하도록 하였다.
💡 BFS 장점과 단점
- 장점
- 모든 경로를 탐색하기에 여러 해가 있을 경우에도 최단 경로임을 보장한다.
- 노드의 수가 적고, 깊이가 얕은 해가 존재할 때 유리하다.
- 최단 경로가 존재하면 깊이가 무한정 깊어진다고 해도 답을 찾을 수 있다.
- 단점
- 노드의 수가 많을수록 탐색 가지가 급격히 증가함에 따라 보다 많은 메모리를 필요로 하게 된다.
✔️ 이진 트리(BST) & DFS 활용
[Leetcode] 700. Search in a Binary Search Tree - https://leetcode.com/problems/search-in-a-binary-search-tree/description/
LeetCode - The World's Leading Online Programming Learning Platform
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
def DFS(node):
if not node:
return None
# 값 일치하는 것 찾으면 node return
if node.val == val:
return node
# 현재 노드의 값이 타겟보다 크면 왼쪽 으로 탐색
if node.val > val:
return DFS(node.left)
# 현재 노드의 값이 타겟보다 작으면 오른쪽 으로 탐색
if node.val < val:
return DFS(node.right)
return DFS(root)문제 설명
BST(Bianry Search Tree)가 주어진다. 어떠한 수 val 이 주어지는데, val 값에 해당하는 노드를 반환하는 문제이다.
문제 해결
트리를 최상위 루트 노드부터 DFS로 탐색한다. BST(이진 탐색 트리)는 부모의 키 값이 왼쪽 자식 노드의 키 값보다 크며, 부모의 키 값이 오른쪽 자식 노드의 키 값보다 작다.
그래서 트리를 탐색할 때, 우리가 찾는 'val' 값이 본인 노드보다 크다면 오른쪽 으로 탐색, 작다면 왼쪽으로 탐색하면 된다.
이렇게 탐색하게 되면 전체 노드를 탐색하는 것보다 시간 복잡도가 O(N) -> O(log N)으로 줄어들게 된다.
💡 BST(Binary Search Tree)의 단점
여기서 알아 둬야 할 점은, BST의 시간복잡도가 무조건 O(log N)이 아니라는 점이다. 아래 그림을 보자.
이진 탐색트리에 새로운 노드가 삽입되면 부모 노드보다 작은 값은 왼쪽, 큰 값은 오른쪽으로 추가하게 된다.
위 그림처럼, 최악의 경우는 이진 탐색트리가 한쪽으로 치우치게 되는데, 이를 Skewed Binary Search Tree(편향 이진 탐색 트리)라고 한다. 이 경우는 특정 노드를 탐색하는 시간이 O(N)이 소요된다.
이를 개선하기 위해 나온 트리가 균형 이진 탐색 트리(Balanced Binary Search Tree)이다.
✔️ 글을 마치며
문제를 풀 때, DFS를 사용할지 BFS를 사용할지 구분을 지어야 할 것 같다. 최단 거리 문제 같은 경우는 BFS로 풀고, 이동과정에 가중치나 조건이 붙는다면 DFS로 푸는 게 좋을 것 같다. 미로 찾기로 예를 들면, 미로 찾기의 출구 최단 거리를 구하는 문제는 BFS로 풀고, 미로 찾기의 출구가 존재하는지 안 하는지의 여부는 DFS로 풀면 좋을 것 같다.
또한 알고리즘 문제를 풀 때, 문제를 해결하는 데에만 초점을 맞추지 말자. 그 문제 속에서 배울 수 있는 개념들이 많다. 자료구조의 장점과 단점을 확실하게 공부하고, 상황에 맞는 최적의 자료구조와 알고리즘을 찾는 연습이 더 필요할 것 같다.